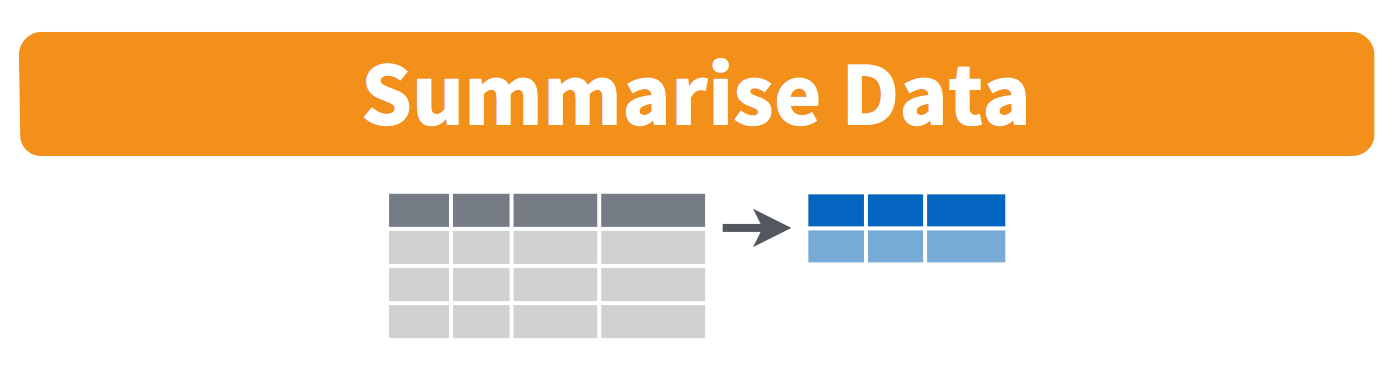
summarise() function. Note that in the output, only one row is returned, and the number of columns is not necessarily the same.
Data is a valuable resource, but raw data alone is not always useful to anyone. When was the last time scrolling through a large spreadsheet of information told you something particularly interesting about the world? Data sets usually need to be arranged in some way in order to gain insight from them.
In this class, we’ve already encountered one technique for identifying patterns in large data sets: data visualizations! In today’s lab, we’ll practice another technique for arranging data in order to make sense out of it: computing summary statistics.
When you compute a summary statistic, you are taking the values from many different individual observations of one variable, and “boiling them down” to one representative value. What kind of summary statistic you choose to compute depends on what type of variable you want to summarize, and what you want to learn about that variable.
In many cases, something as simple as comparing the average value of a single variable across different groups produces enough information to draw insight.
The purpose of this lab is to practice computing summary statistics for categorical and numeric variables, including summaries of specific groups of observations within a larger data set. You will also practice recognizing which summary statistics are appropriate for specific types of data-based questions.
After completing this lab, you should be able to use R’s built-in summary functions, together with the group_by() and summarize() functions from the dplyr package, to compute a variety of summary statistics.
![]()
You will know that you are done when you have created a rendered HTML document where the results match the example solutions.
Sections 4.4 - 4.5 in R for Data Science are good additional resources that augment the material covered in this lab.
Download the Lab 5 template.
Before you open the template, use your computer’s file explorer to move the template file you just downloaded out of your Downloads folder and into your SDS 100 folder.
Then, open RStudio, and make sure you’re working in the SDS 100 project. If the Project pane in the top right of your RStudio window doesn’t show “SDS 100”, go to Open Project as shown below and navigate to your project.
Finally, open the template file in RStudio. The easiest way to do this is to go to the Files pane in RStudio, find the lab_05_summarizing.qmd file from the list, and click on it.
If you don’t see a file named lab_05_summarizing.qmd in the list, make sure you did steps 2 and 3 correctly. If you’ve double-checked your steps, and still don’t see it, ask your instructor for help.
A list of all the summary statistics in the world would go on for pages and pages. Table 1 below lists 7 summary statistics that are useful in a wide variety of contexts. In R, each of these summary statistics is computed by using a different R function on the variable you want to summarize.
| Statistic | Meaning | R Function |
|---|---|---|
| Total | The sum of all values in a numeric variable | sum() |
| Mean | The average value of numeric variable | mean() |
| Median | The “middle number” of a numeric variable | median() |
| Variance | The spread of a numeric variable (in squared units) | var() |
| Standard Deviation | The spread of a numeric variable (in the same units as the variable) | sd() |
| Count/Frequency | The number of times a particular category value occurs | n() 1 |
| Proportion | What percentage of the total number of observations belonged to a particular category | n()/sum(n()) 2 |
As you can see, some summary statistics are useful for describing numeric variables, while others should be applied to categorical variables. Some summary statistics (like the mean or the proportion), tell you what sort of observations are “typical” or “likely,” while others (like the variance or standard deviation) help you understand how generally similar or dissimilar your observations are to one another.
SaratogaHouses data setWe’ll get some practice using R’s summary functions by applying them to the SaratogaHouses data set from the mosaicData package (which you may have to install). This data set holds information about 1,728 houses for sale in Saratoga County, of New York State during 2006. To learn more about each of the 16 variables that were measured for each house, you can open the documentation page for these data using the ?SaratogaHouses command in the R console.
Load the mosaicData R package in your Quarto document, and then visit the documentation page for the SaratogaHouses data set.
Import the Saratoga Houses data set into your environment using the command SaratogaHouses <- mosaicData::SaratogaHouses in your Quarto document. Use nrow() to compute the number of rows in SaratogaHouses.
summarize()Regardless of which particular summary statistic you want to compute, or which variable in your data set you want to summarize, you’ll always need use the summarize() function from the dplyr package to help.
Calls to summarize() will almost always have three ingredients:
SaratogaHouses)median())price)median_price).Figure 1 illustrates the logic of the summarise() function. Notice that (in the absence of any row groupings defined), summarize() returns a single row of data. This is because the summary function you used as your second ingredient (e.g., mean()) above reduces multiple values in a variable into a single value.
summarise() function. Note that in the output, only one row is returned, and the number of columns is not necessarily the same.
What was a “typical” or “likely” home price in Saratoga County in 2006? One way to answer this question would be to compute the median price across all the homes represented in the SaratogaHouses data set. How could we compute this value in R?
Since the median is a summary statistic, and the price variable lives inside the SaratogaHouses data set, we’ll need to use the summarize() function to help us compute the median price. Let’s think about what the 3 “ingredients” we’ll need are:
SaratogaHouses data setmedian() functionprice column of the Saratoga Houses data set.median_price.The example below shows you how to combine these 4 “ingredients” in code to calculate the median price. Note that you must load the dplyr package (included in the tidyverse) for this example to work! If you don’t, you’ll get an error message saying could not find function “summarize”.
library(tidyverse)
SaratogaHouses |>
summarize(median_price = median(price)) median_price
1 189900So, we’ve learned that a “typical” home price is $189,900. Notice also that we’ve also followed “best practice” guidelines, and named our summary statistic median_price (an informative name, with no spaces or special characters in it).
Now, it’s time for you to try answering some questions about these data by computing summary statistics.
How old was a “typical” home in Saratoga County during 2006?. To find out, use summarize() to compute the median age of all the homes in the SaratogaHouses data set. Be sure to think about what “ingredients” you need to supply for your code to work!
What was the average amount of living space of a home for sale in Saratoga County during 2006? Write your own code “from scratch” to compute this summary.
Be sure to think about:
More often than not, an entire data set is a bit too complex to be well-represented by a single number. For example, in the previous section we computed the median price of all the homes for sale in Saratoga County during 2006. In other words, we treated all the homes in the data set like one big group of homes when we computed the median price.
This isn’t wrong to do, but it does ignore some of the complexity in these data. Using one median price to represent all the homes can ignore other ways in which the homes are different from one another. Some homes are bigger than others, some homes have more bedrooms and bathrooms than others, and these differences may be associated with noticeable differences in the price. For example, larger homes will almost certainly cost more than smaller homes, and homes with more bedrooms will almost certainly cost more than homes with fewer bedrooms.
Understanding how the various attributes of a home contribute to its price requires multivariate thinking, which is a crucial learning goal for statisticians and data scientists.
If we want to see how the price of a house changes across different categories of houses, we must take into account which group each house belongs to when computing our summary statistics. In other words, we want one summary computation per group, rather than one overall summary. But as we’ve learned, R’s summary functions like mean() and median()always take many observations and “boil them down” to one number. How can we modify our coding to compute one summary per group instead?
Thankfully, we don’t actually need to change anything about how we use the mean() or median() functions, or anything about how we use the summarize() function. What we need to do is divide the data up into smaller groups before that data reaches the summarize function. This may sound complicated, but it’s actually as easy as adding one single line of code to our previous examples. What we need is the group_by() function!
Figure 2 illustrates the logic of the group_by() function. group_by() on its own doesn’t do much, but when combined with summarize(), it can be a powerful way to summarize data.
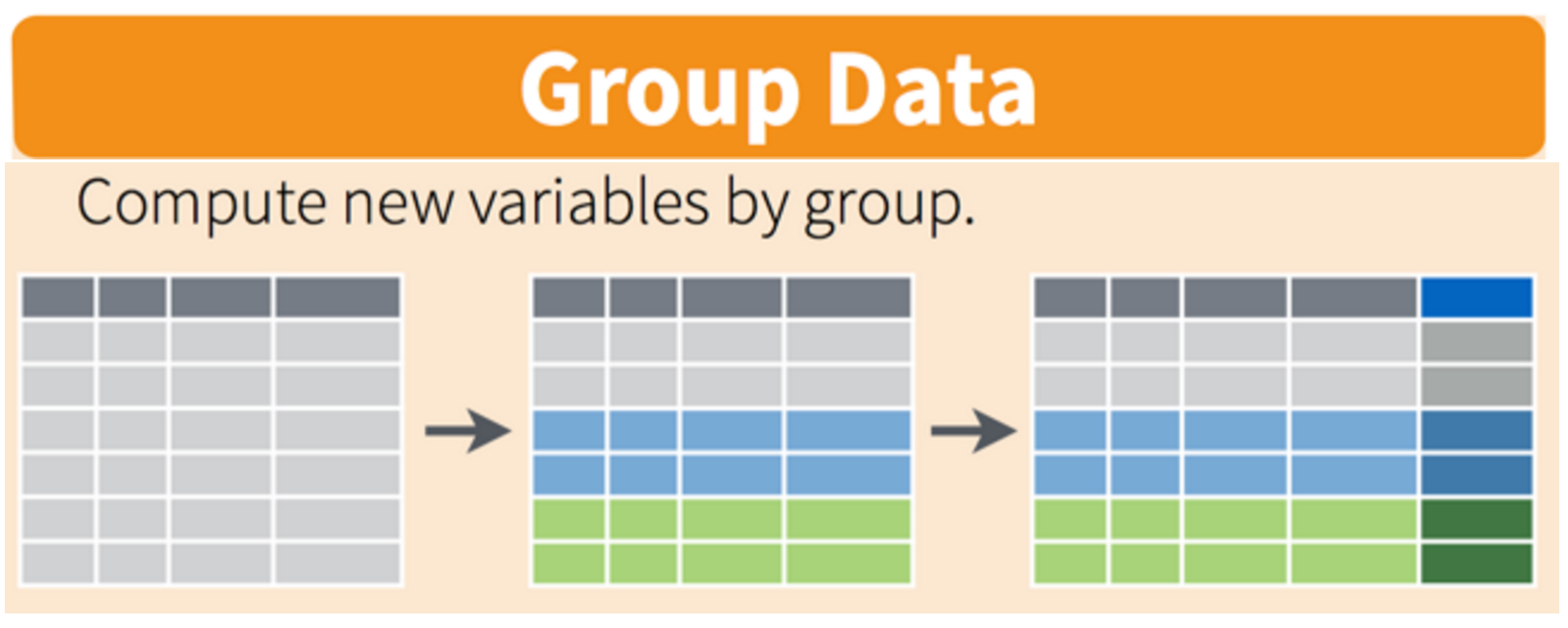
group_by() function.
Let’s add a little nuance to the first question we asked about these data. Instead of asking “What is the typical price of a home?,” let’s ask: “does the typical home price depend on the number of fireplaces it has?”.
Looking through the SaratogaHouses data set and examining the fireplace variable, we see that there are 5 different groups of homes: homes with 0, 1, 2, 3 or 4 fireplaces in them. So to answer our question about these data, we take into account whether a home has 0, 1, 2, 3 or 4 fireplaces when computing the median price.
We can incorporate this information by grouping the data according to the fireplace variable and then summarizing the price variable.
SaratogaHouses |>
group_by(fireplaces) |>
summarize(median_price = median(price))# A tibble: 5 × 2
fireplaces median_price
<int> <dbl>
1 0 158250
2 1 215700
3 2 277750
4 3 360500
5 4 700000Since there were five different groups of homes (one group for each number of fireplaces), our resulting summary has 5 rows in it: one median price for each type of home. We can see that the price of a home strongly depends on the number of fireplaces it has: homes with more fireplaces have higher median prices.
Figure 3 provides a simple schematic for this calculation (based on a small subset of the data).

SaratogaHouses data set by the fireplaces variable, then summarizing each group using the median price.
Now, it’s time for you to practice computing your own group-wise summaries.
Does the price of a home depend on the type of heating system it has?
To find out, insert a new code chunk into your Quarto document, and copy the code template below into this new code chunk.
SaratogaHouses |>
group_by(______) |>
summarize(median_price = median(price))Then, modify the “blanks” in this template to compute the median price of of a home, given its type of heating system.
Be sure to look back at the variables in the data set to figure out which one can tell you what type of heating system a home uses.
How does the average size of a home depend on the number of bedrooms in the home? Write your own code “from scratch” to compute this summary. Be sure to think about
For almost all of R’s summary functions, you have to place the name of the variable you want to summarize inside the parentheses of the summary function you’ve chosen. For example, whenever we’ve computed the median price, we always wrote price inside the parentheses for the median() function.
However, there are exceptions to this rule among R’s most commonly-used summary functions. The most common is the n() function. The n() function counts the number of rows within each group of your data, which is very useful for summarizing categorical variables. In fact, knowing the number of observations in each group is so important that we recommend computing them every time you use the summarize() function, even when it may not be immediately obvious to you why that information is important.
Always compute the number of observations in each group with the n() function every time you use summarize().
For example, we could add the n() function to our previous example of computing the median home price grouped by the number of fireplaces, to learn exactly how many 0, 1, 2, 3 and 4 fireplaces homes exist in the data set. Since each row represents one home, counting the number of rows is the same as counting the number of homes!
SaratogaHouses |>
group_by(fireplaces) |>
summarize(
median_price = median(price),
num_homes = n()
)# A tibble: 5 × 3
fireplaces median_price num_homes
<int> <dbl> <int>
1 0 158250 740
2 1 215700 942
3 2 277750 42
4 3 360500 2
5 4 700000 2Not surprisingly, most homes have no fireplace, or just one fireplace. But we also learned that there were only two homes with three fireplaces, and only two more with four fireplaces. This is important because it tells us that the mean home prices are based on only two values (each), and are thus not robust. Furthermore, this example highlights how the syntax for using n() function is different from others: you don’t put anything inside the parentheses for the n() function!
This might seem confusing at first, but makes sense when you think about it for a moment. Since the n() function is just counting the number of rows, it doesn’t need to know anything about the contents of those rows. Your rows could have words, numbers, or pictures in them—but the n() function simply ignores all that, and counts how many rows there are. You don’t need to provide it any specific variables for it to do its job.
Which type heating fuel is used the most frequently? We can use the n() function to find out!
Investigate by inserting a new code chunk into your Quarto document, and copy the code template below into this new code chunk.
SaratogaHouses |>
group_by(____) |>
summarize(num_homes = ____)Then, modify the “blanks” in this code chunk to count the number of homes that use electric, gas, or oil as their heating fuel.
Be sure to look back in the documentation for the SaratogaHouses data set to figure out which variable measures what kind of fuel a home uses, so you know which variable to group the data by!
Write your own code “from scratch” to calculate how many homes in the data set do and do not have a waterfront on their property.
When dealing with real-world data, it’s usually the case that we don’t have values for every observation of every variable. It could be that the given variable doesn’t apply to unit being observed, but usually, it’s just that the value is unknown for some reason. These unknown values are commonly referred to as missing data. Missing data is indicated in by using NA in place of the data.
Missing values present a tricky complication for summarizing variables. The SaratogaHouses data set doesn’t have any missing data, but the penguins data set in the palmerpenguins package does. So, we’ll use the penguins data to explore the problems that emerge when working with data that has NA values in it.
Insert a new code chunk into your Quarto document, and copy code below into that code chunk. Press the green “play” button to run this code, and then explain in words what this code is doing.
penguins <- palmerpenguins::penguinsThis code reaches into the palmerpenguins package, makes a copy of the penguins data set, and stores this copy of these data as an object in the environment named penguins.
Let’s start by using the group_by() and summarize() functions to examine the average body mass of each penguin species:
penguins |>
group_by(species) |>
summarize(avg_body_mass_g = mean(body_mass_g))# A tibble: 3 × 2
species avg_body_mass_g
<fct> <dbl>
1 Adelie NA
2 Chinstrap 3733.
3 Gentoo NA Unfortunately, only the average mass for Chinstrap penguins is reported; the average mass for Adelie and Gentoo penguins are both NA. This happens because the mean() function (and other similar functions, like sum() and sd()) output NA if there are any NA values in the input.
So, what can we do to find the average mass of Adelie and Gentoo penguins? Before taking any action, it’s worth taking a step back and thinking carefully about the missing values in the data.
When you see NA values in your data, it’s important to understand more about why they might appear. If we were looking at a variable measuring the size of a penguin’s eggs, we would expect to see NA values in the rows representing male penguins. However, we’re currently trying to summarize mass, and we would expect mass to be observable and applicable for all penguins.
We also want to look at where and how often these NA values appear. One way to do this is filtering your data set to show only observations where a certain variable is NA. We can do that by using the is.na() function within the filter() function. The below code shows an example of this being used to show only penguins with missing bill_length_mm.
penguins |>
filter(is.na(bill_length_mm))Use the is.na function and the penguins data set to see only penguins with missing body mass.
You should see that there are only 2 penguins missing body mass observations, one Adelie and one Gentoo penguin, compared to 1728 total penguins. With so few missing values, it’s unlikely that the average mass would change substantially even if the masses of these two penguins were serious outliers. In this type of case, it’s often okay to exclude the NA values and take the average of all known observations. If a large portion of the data (either overall or within a group) were missing, we might not want to do this.
drop_na()We can exclude NA values from our computations by using the drop_na() function in our pipeline before using the summarize() function. the drop_na() function comes from the tidyr pacakge, which is part of the tidyverse. Since you’ve already loaded the tidyverse, you’re already ready to use the drop_na() function.
The code below demonstrates how to use the drop_na() function to remove all the misssing body masses before averaging them:
penguins |>
group_by(species) |>
drop_na(body_mass_g) |>
summarize(avg_body_mass_g = mean(body_mass_g))# A tibble: 3 × 2
species avg_body_mass_g
<fct> <dbl>
1 Adelie 3701.
2 Chinstrap 3733.
3 Gentoo 5076.The drop_na() function take a comma-separated list of variable names as it’s input, so you can filter the missing values from multiple variables at the same time. For example, we could remove the observations that have missing values in the sex variable and the observations that have missing values in the body_mass_g variable like this:
drop_na()penguins |>
group_by(sex) |>
summarize(avg_body_mass_g = mean(body_mass_g))# A tibble: 3 × 2
sex avg_body_mass_g
<fct> <dbl>
1 female 3862.
2 male 4546.
3 <NA> NA drop_na()penguins |>
group_by(sex) |>
drop_na(sex, body_mass_g) |>
summarize(avg_body_mass_g = mean(body_mass_g))# A tibble: 2 × 2
sex avg_body_mass_g
<fct> <dbl>
1 female 3862.
2 male 4546.Compute the average flipper length for Adelie, Gentoo and Chinstrap penguins, and the number of penguins of each species. Discard any observations with missing flipper lengths.
Double check that you’ve completed each exercise in this lab, and have written a solution in your Quarto document. If so, render your Quarto document into an HTML file. Then, check your work for each exercise by comparing your solutions against out example solutions.
Complete the Moodle quiz for this lab.
If you have not yet formed a group, you should continue seeking out classmates to work with on the final project.
During this week, you should also expect to receive information from your instructor about whether the data you submitted for approval is suitable, or if you need to find another data set to use.
See the Final Project page for full instructions regarding Phase 1 of the project.
To prepare for next week’s lab on polishing data visualizations, we encourage reading Chapter 2: Data visualisation from R for Data Science.